Authors: Fengchen Liu, Jordan Jung, Shawfeng Dong, Tin Ho
Published on February 10, 2022.
Automated Machine Learning (AutoML) frameworks aim to automate tasks so non-experts can take advantage of machine learning on a large scale. There are a vast amount of these frameworks on the market, and all major cloud providers have their own Computer Vision AutoML implementations: Google Cloud Platform (GCP) offers AutoML Vision and AWS has Amazon Rekognition. This article focuses on using GCP AutoML to illustrate how easy and quick it is to train and deploy a computer vision model for object detection.
The Use Case
Macromolecular Crystallography is the use of X-rays to study the structures of proteins, DNA, and RNA at an atomic resolution. The technique relies on alignment of crystal samples within high energy X-rays beams which are produced at the synchrotrons, such as Berkeley Lab’s Advanced Light Source (ALS). This step has historically been performed through a manual click-to-center strategy or traditional machine vision strategies based on edge detection and other rigid procedural techniques. Dr. Scott Classen, a Biophysicist Research Scientist in the Molecular Biophysics and Integrated Bioimaging Division comments about how tedious operating ALS Beamline 8.3.1 used to be:
“Traditionally, a person would put their sample onto the beam line and then high magnification cameras would allow you to see your sample. The person would then have to click on the part of the sample they wanted to shoot with x-rays and various motors would position your sample in the X-ray beam for the experiment. And that’s fine, it still works that way to a large degree, but it’s inefficient and there are many other things you could be doing instead of clicking samples on the screen. Also people get very tired at 2am in the morning so sometimes they make mistakes. Or they just leave the beam line so it’s not being used – So it’s not a very efficient use of beam time.”
Dr. Scott Classen
To address this problem, Dr. Classen came up with the idea to automate this process of X-raying samples. LoopDHS is a machine learning (ML) program capable of expediting the selection process during X-ray preparation. According to Classen, the goal of LoopDHS is to use machine learning and object detection / object classification to help locate the loops (the small instruments holding the protein crystals). So if researchers can locate these objects using an automated machine learning technique and interface that procedure with the LoopDHS control system, then all of the user samples can be looped in a more automated way. This new technique will make better use of the beam time and it will also free up researchers to do more intelligent things with their brains rather than clicking on stuff!
After an attempt to write a ML program from scratch, Dr. Classen reached out to collaborate with ScienceIT consultants Shawfeng Dong and Fengchen Liu to use AutoML machine learning for the LoopDHS project. As part of the effort, IT student intern Jordan Jung developed a training dataset for the model to improve the accuracy. These developments moved the project forward in a significant way.
The following example explains the steps to use AutoML machine learning to automatically locate the loops in Figure 1.
AutoML Example
Fully automated and unattended Macromolecular Crystallographic data collection relies on robust alignment of crystal samples within the X-ray beam. Machine Learning (object classification and detection) has been used in the sample centering step. In this use case, the dataset contains 1500 annotated images of 2 classes of samples: nylon loop and MiTeGen loop (Figure 1).
| Nylon Loop | MiTeGen™ |
 |
 |
Figure 1. Different kinds of loops (Nylon & MiTeGen™).
The Process: Create Dataset
The first step is to create a dataset via the GCP Vertex UI or over Vertex AI SDK. Figure 2 below shows the options available during the process of creating a dataset. Currently, GCP AutoML supports Image, Tabular, Text and Video models. In this case, Image Object Detection is selected.
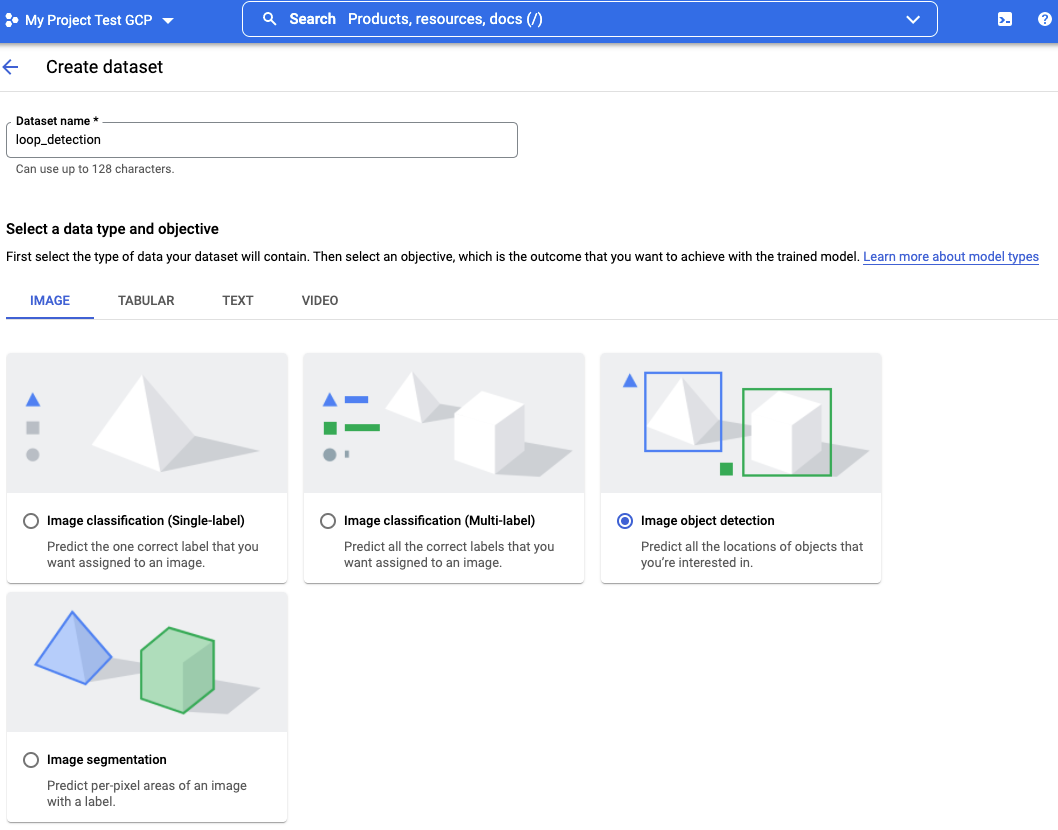
Figure 2. Dataset creation
Dataset can be uploaded directly to the GCP Vertex AI through the web UI or using the SDK. Web UI is used here since it offers the option to import images from Google Cloud Storage in batches via JSON Lines while the labels and bounding boxes are defined by the schema.
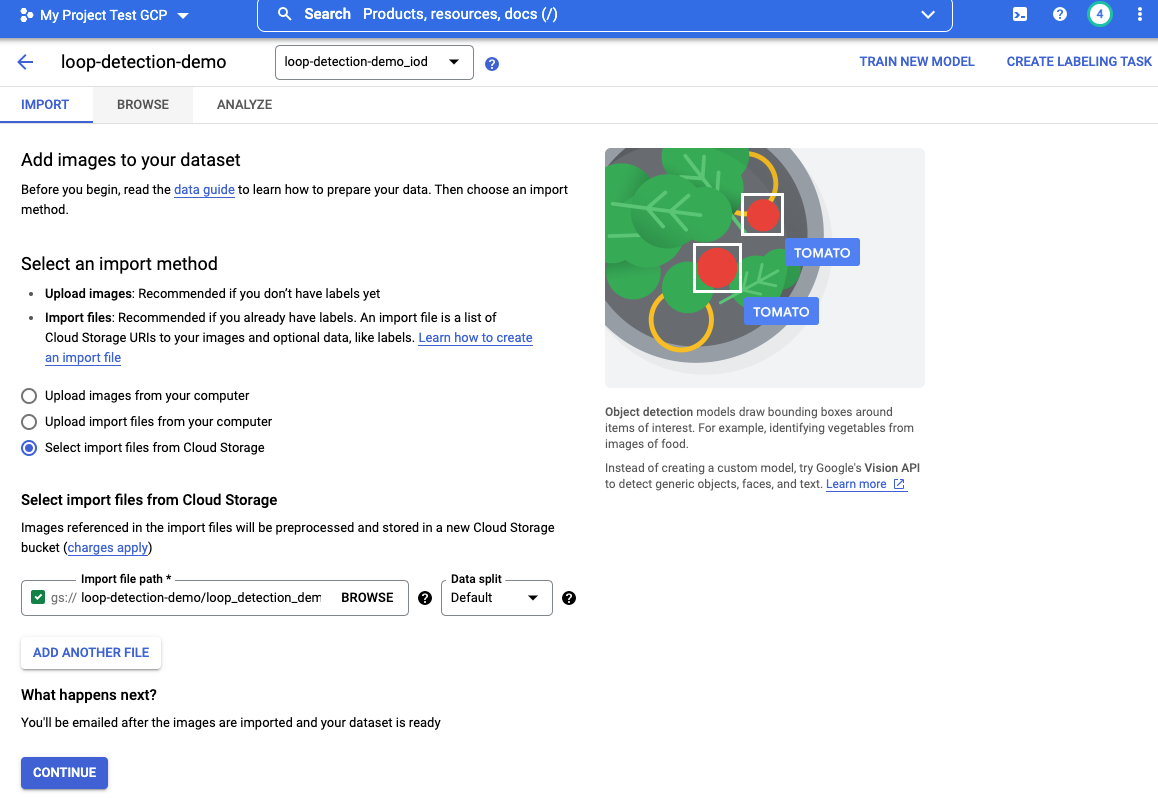
Figure 3. Import images
The development team imported 100 random images of nylon loop and 100 random images of MiTeGen loop (Figure 1). Each image has 704×408 pixels and one nylon loop or MiTeGen loop in a bounding box larger than 8×8 pixels. Once the import is completed, we can see the images with bounding boxes in Vertex AI Datasets (Figure 4). Those 200 images were randomly split into train/validation/test sets: 160/20/20.
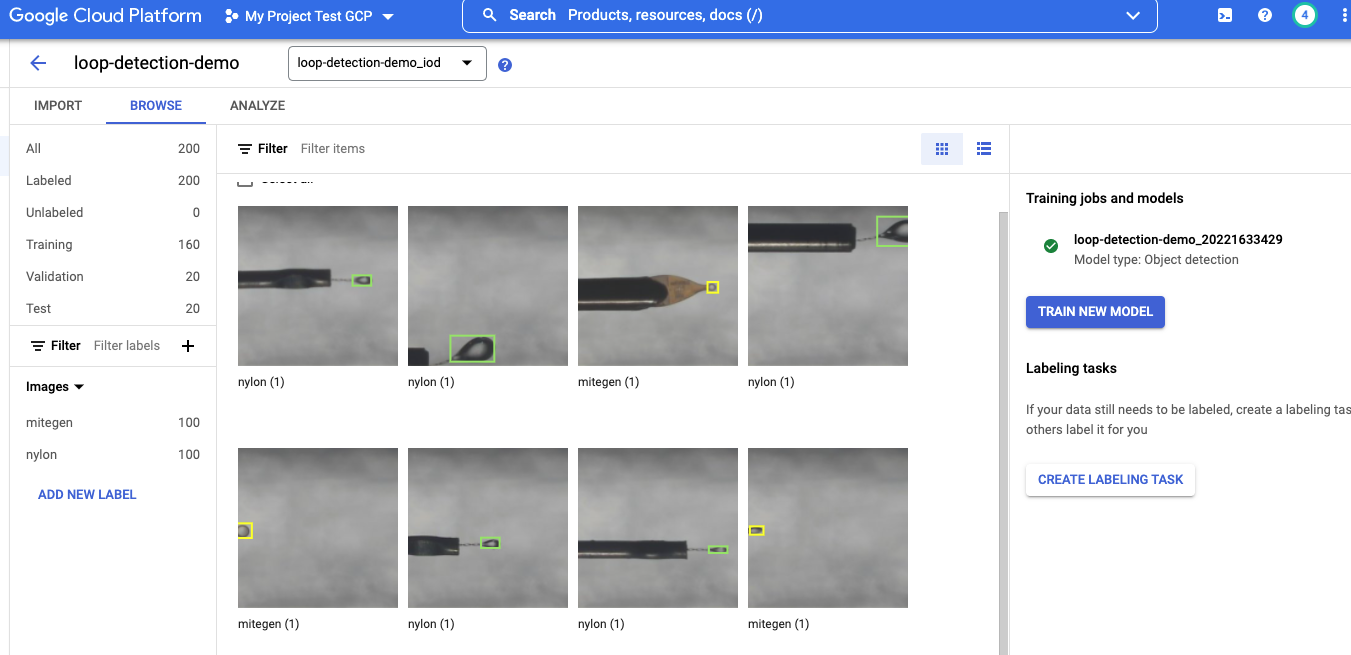
Figure 4. Uploaded images
After selecting a single image, users can see the bounding box, draw a new bounding box, change the object’s label, or select which set (train/validation/test) this image should be used for model training (Figure 5).
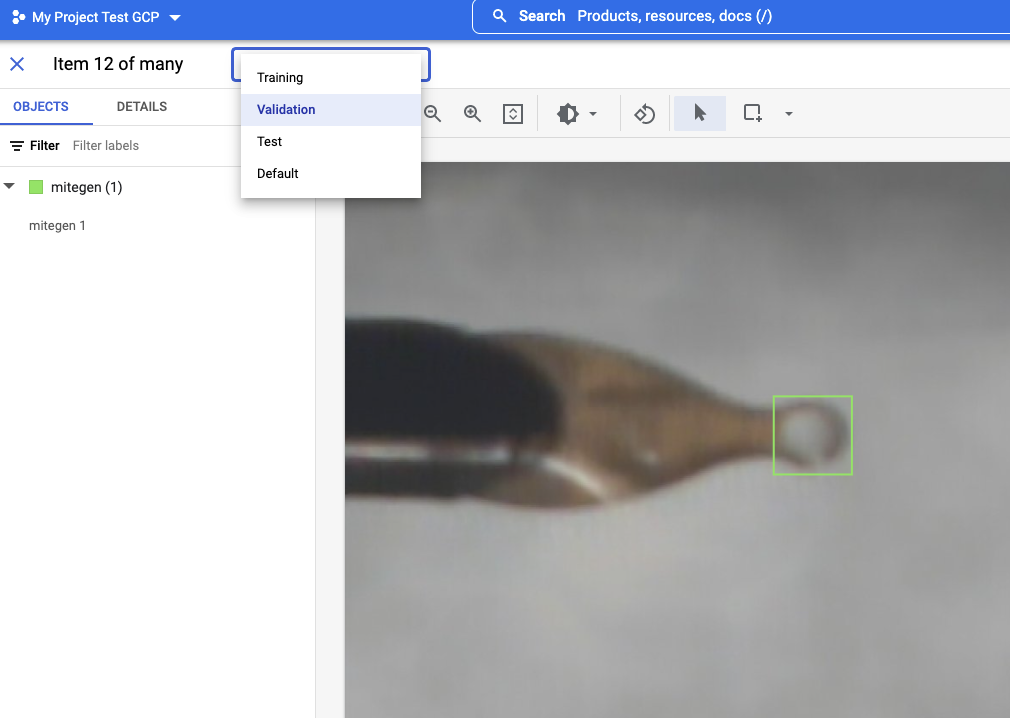
Figure 5. Bounding box for a MiTeGen loop image
Model Training and Evaluation
There are 3 options available in the GCP AutoML. The first one is the AutoML model which allows users to train a model without needing to write any code. The second one is the AutoML Edge model which allows users to export the model after training and to deploy it on an edge device. The third one is Custom Training, which is for advanced users who need more control over the training process, and have pre-built models in scikit- learn, TensorFlow, PyTorch or XGBoost.
Figure 6. Train new model
In this case, the AutoML model was selected and the training was completed within 1 hour.
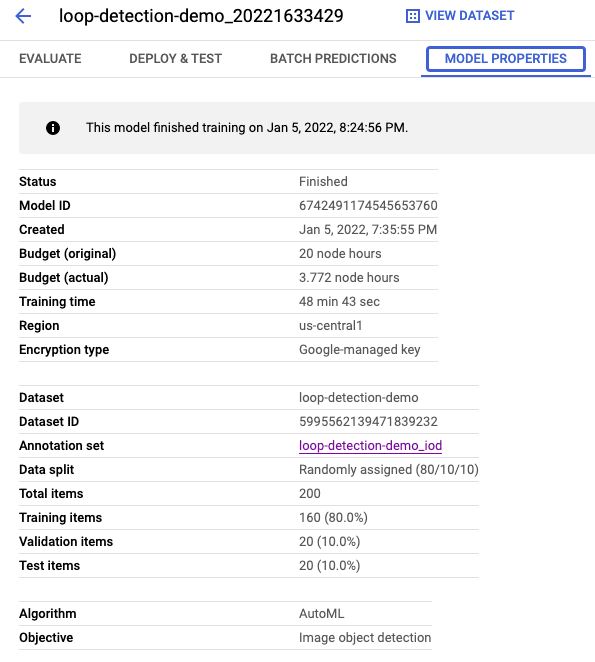
Figure 7. Model properties
AutoML image object detection model provides different evaluation metrics (such as: PR-AUC, precision, recall, confidence threshold and IoU threshold) for users to evaluate the performance of the trained model before deployment. The table below shows the evaluation output from the trained AutoML model on the loop detection dataset. The overall performance of the trained model: 95% precision, 90% recall, and 76% PR-AUC. Each label shows the evaluation metrics: 89% precision, 80% recall and 74% PR-AUC for the MiTeGen loop; 100% precision, 90% recall and 77% PR-AUC for the nylon loop.
The following screenshot (Figure 8) shows objects classified as false positives, false negatives, and true positives. Evaluation revealed that the false positives and false negatives are images of the edge of MiTeGen loop (90 degree rotation of the standard MiTeGen loop shown in Figure 1). In this case, adding more ground truth images of the edge of MiTeGen loop that are similar to those false negatives and false positives may improve the model prediction accuracy.
| Metrics | MiTeGen Loop | Nylon Loop | All Loops |
| PR-AUC | 74% | 77% | 76% |
| Precision | 89% | 100% | 95% |
| Recall | 80% | 90% | 90% |
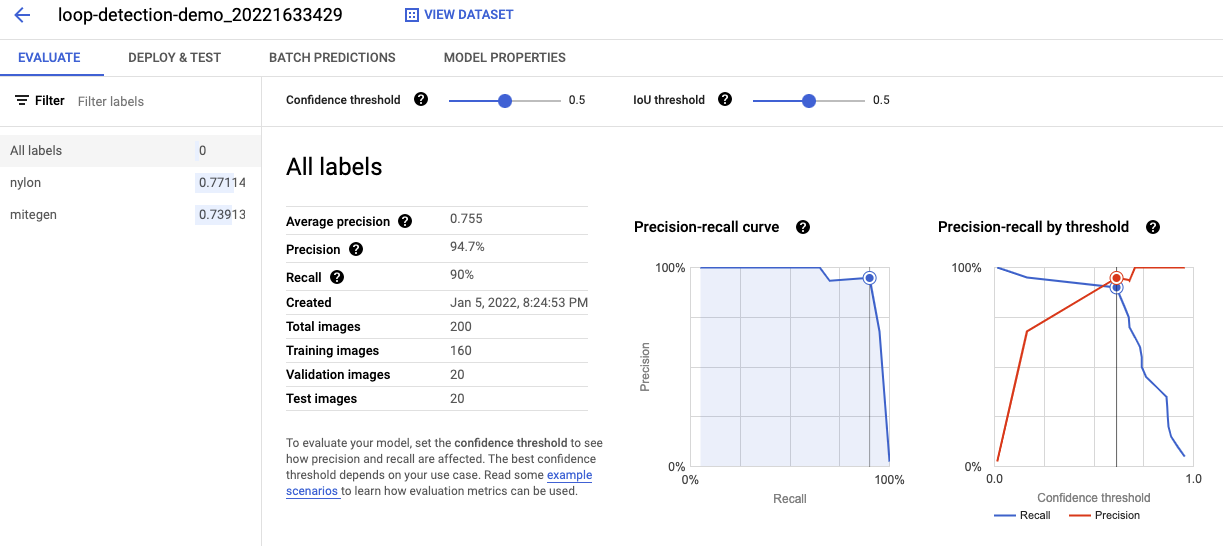
Figure 8. a) Model evaluation output: all loops
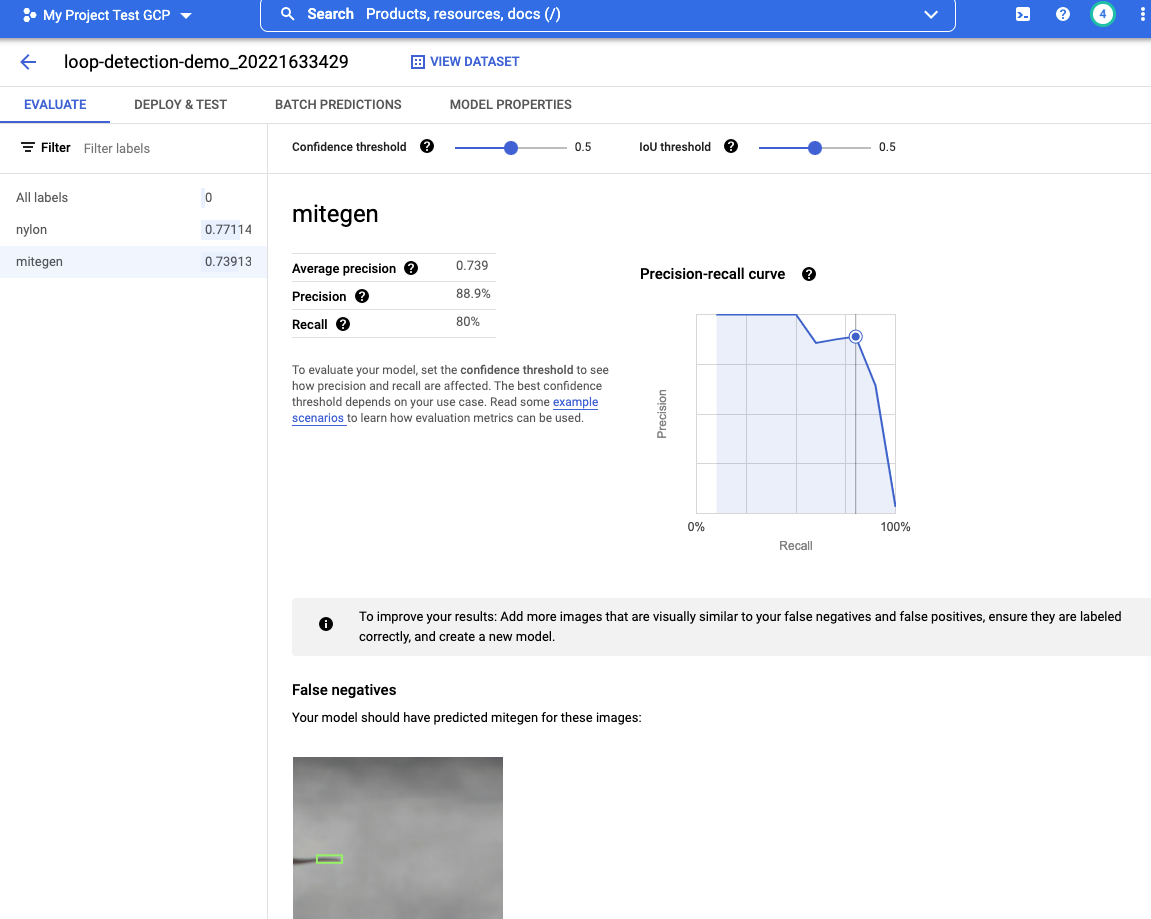
Figure 8. b) Model evaluation output: the MiTeGen loop
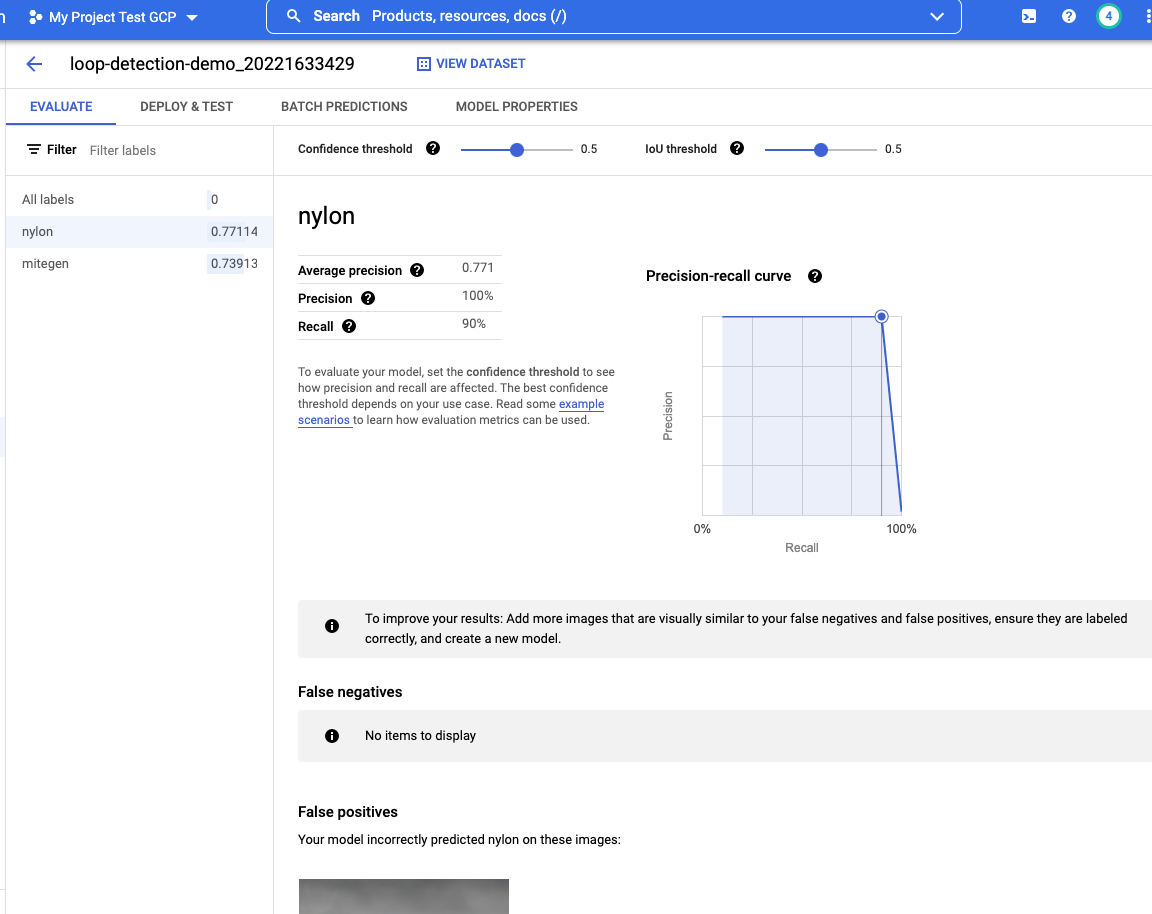
Figure 8. c) Model evaluation output: the nylon loop
Deployment
Initial training for the demonstration object detection model is complete and seems to be working as expected. The next step is to deploy a prediction endpoint. Once the deployment process has finished, the model can be used to get predictions on new data by either uploading the images or calling the API.
Figure 9. Deploy and test.
Summary
This article presents one example of how easy and quick it is to build an object detection model. The GCP AutoML model can be quickly trained, evaluated and deployed by researchers with minimal ML expertise or effort.
For LoopDHS, the actual AutoML edge model was trained with a larger dataset than the example here which resulted in better performance (accuracy > 95%); the image of the trained edge model was downloaded and is now deployed on a local Docker at ALS beamline 8.3.1.
Dr. Classen remarks, “I’m adding this ability to the beam line so that everybody will be able to do automated data collection. Right now people who are using the beam line have to sit in front of the computer and click on their sample. Once this is fully implemented, they’ll be able to say, Okay, I see my list of 50 or 60 samples, I’m going to hit the Go button, and then I’m going to go have a sandwich. And then the beamline will collect all of their 50 or 60 data sets, without any human intervention that will be fully automated hands off data collection. That’s the cool part.”
Read more HPC News articles.

