A Very Brief History of Image Storage at the Lab
Berkeley Lab is home to an invaluable visual history of science with over 800 thousand online images (photos.lbl.gov) and over 1 million additional images in a variety of film formats.
Knowing where and how to even begin the process of searching for images can seem like a frustrating and time consuming task.

The photography archives begin with the founding of the Lab in 1931. As the Lab grew the volume of images expanded along with it. The methods and standards for organizing and indexing the photo collection changed as the methods for storing and indexing images moved from a physical film-based system to today’s digital storage systems.
The online photography archive in its present form, hosted by the vendor WebDam, was set up in 2010. Modeled on the existing film-based storage filing and indexing system, WebDam features an intuitive folder-based structure using the image creation date as the main sorting method, with image metadata (such as captions, keywords, image or project name, etc.) available as a secondary search method.
The gradual movement from a physical to a digital asset system marks an important milestone in stewarding the Lab’s history. However, recent analytics and feedback indicate most users of the site are not taking full advantage of the rapid improvements in digital asset management, information architecture, and robust search engines currently available though the photo archive
Many users report starting a search for images by clicking through the date-based folders one at a time, often spending needless time browsing for a suitable image. The search features on the site do not seem to be well utilized.
Improved Search Tips
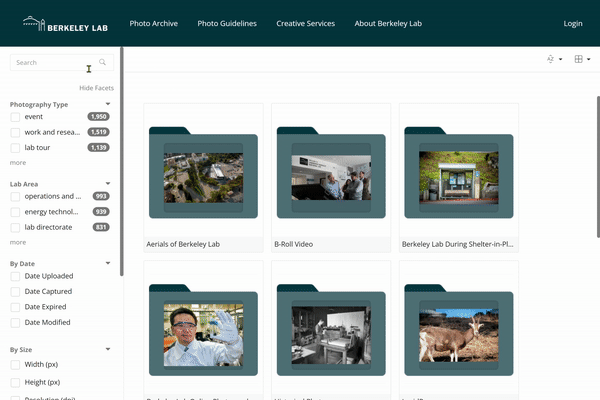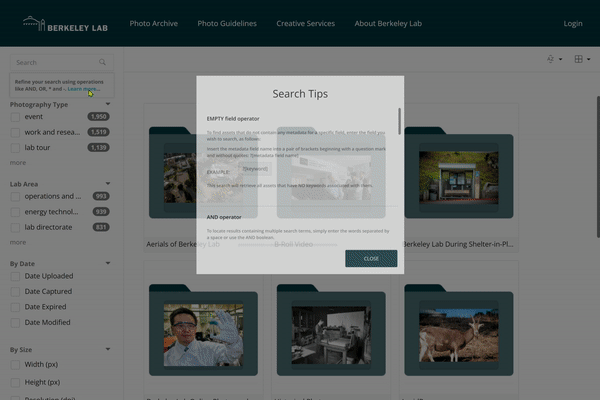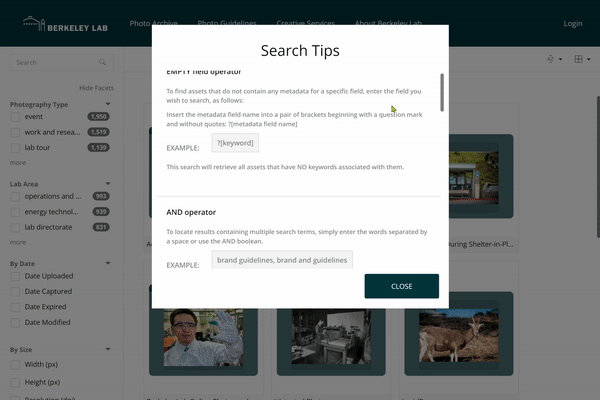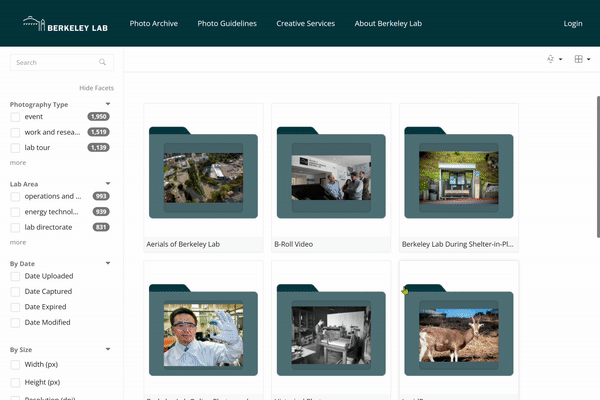
In an effort to improve the utility of the online photo archive, IT is rolling out new Search Tips and Frequently Asked Questions (FAQ) pages on the site.
These guidelines detail the various ways users can search the site for images and download assets from the Photo Archive. Notes on key features and recent improvements are included.
The updated photo archive search engines leverage machine learning and artificial intelligence tools to better understand the image assets and search needs of the people who use the site by improving automated keyword suggestions and other search aids. These tools will improve as more users take advantage of these powerful search features, allowing the algorithms to make better predictions on search results, face recognition, suggesting keywords, and matching similar assets in results.
Looking Toward the Future

Improving the Lab’s photo archive will be an ongoing project. Due to the vast difference in the quality and governance of metadata over the years, changes to search features will take time to percolate through the entire database. Many of the asset records on the site are using outdated, inconsistent, and all too often, non-existent keywords, captions, and other metadata. These records will need to be manually evaluated and corrected.
IT is working with the archive vendor to implement updated metadata governance and indexing standards which will make learning how to utilize the photo archive much less daunting and ensure this invaluable documentary history is fully accessible to future generations to follow.

